Tạo một biểu đồ là việc đơn giản, tuy nhiên tạo một biểu đồ đúng đưa ra một thông điệp rõ ràng, đó là một thách thức thực sự. Với mỗi thể hiện, ta có nhiều sự lựa chọn, trước tiên, có rất nhiều loại biểu đồ, mỗi loại biểu đồ, ta có vô hạn các thông số điều chỉnh, bạn có thể thay đổi màu sắc, hình dạng, nhãn, các trục và vân vân ... Sự lựa chọn phụ thuộc 1 là vào dữ liệu, 2 là vào câu chuyện, ý nghĩa mà bạn muốn thể hiện từ dữ liệu đó. Bởi vì có rất nhiều tùy biến, cách tốt nhất là chúng ta phải học chúng từ các ví dụ.
Hãy bắt đầu với đoạn code sau đây để tạo một biểu đồ đường thẳng.
import matplotlib.pyplot as plt
year = [1950, 1951, 1952, ..., 2100]
pop = [2.538, 2.57, 2.62, ..., 10.85]
plt.plot(year, pop)
plt.show()

Nó đơn giản là tạo một biểu đồ thẳng giống như các bài trước mà ta đã thực hành, nhưng bây giờ year và pop là những biến chứa nhiều dữ liệu hơn, nó bao gồm các dự án đến tận năm 2100 được dự báo bởi Liên hiệp quốc. Nếu chúng ta thực thi đoạn code, ta sẽ có được một biểu đồ như trên: nó trình bày được sự tăng trưởng của dân số, sự tăng trưởng này sẽ chậm lại vào cuối thế kỷ. Với biểu đồ này một vài thứ có thể được cải tiến
- Vấn đề thứ nhất sẽ rõ ràng hơn nếu ta cho biết được dữ liệu nào đang được thể hiện đặc biệt là với những người nhìn biểu đồ lần đầu tiên.
- Vấn đề thứ hai biểu đồ thật tự cần thu hút sự chú ý về việc bùng nổ dân số.
Đối với vấn đề thứ nhất, ta luôn luôn cần gán nhãn cho 2 trục, để gán nhãn, ta dùng 2 hàm xlabel() và ylabel(), tham số truyền vào là 1 chuỗi ví dụ như xlabel("year") và ylabel("population"). Tiếp theo ta sẽ thêm tên biểu đồ bằng hàm title(). Các hàm này phải được gọi trước khi gọi hàm show() nếu không thì chúng sẽ không hiện ra đâu đấy. Đoạn code mới như sau:
import matplotlib.pyplot as plt
year = [1950, 1951, 1952, ..., 2100]
pop = [2.538, 2.57, 2.62, ..., 10.85]
plt.plot(year, pop)
plt.xlabel('Year')
plt.ylabel('Population')
plt.title('World Population Projections')
plt.show()

Sử dụng xlabel, ylabel và title ta cung cấp cho người đọc nhiều thông tin hơn cơ bản nhất về biểu đồ của ta. Để đưa ra quan điểm về sự tăng trường dân số, tôi muốn cột y bắt đầu từ 0, làm được điều này tôi sử dụng hàm yticks()
plt.yticks([0, 2, 4, 6, 8, 10])
Tham số đầu tiên là một mảng, ví dụ trên là từ 0-10, khoảng cách là 2 đơn vị. Nếu ra chạy đoạn code này thì biểu đồ sẽ thay đồi, đường cong sẽ được dịch chuyển lên.

Với biểu đồ mới này, ta thấy rõ ràng hơn là năm 1950 nó đã vượt mốc 2.5 tỉ người. Tiếp tục, để rõ hơn chúng ta sẽ nói về đơn vị tính tỉ, ta sẽ thêm tham số thứ 2 trong hàm yticks(), nó là một danh sách trình bày tên của ticks, danh sách này phải bằng số phần tử của danh sách ở tham số đầu, tick 0 sẽ có nhãn là '0', tick 2 có nhãn là '2B', tick 4 có nhãn là '4B', ... khi đó B đại diện cho đơn vị tỉ "billions' .
plt.yticks([0, 2, 4, 6, 8, 10],
['0', '2B', '4B', '6B', '8B', '10B'])

Cuối cùng giải quyết vấn đề thứ 2, thêm một số dữ liệu để nhấn mạnh sự bùng nổ dân số trong 60 năm qua. Trên wikipedia, ta tìm được dữ liệu dân số ở các năm 1800, 1850 và 1900, ta thêm các số liệu này vào đầu của 2 danh sách year và pop.
import matplotlib.pyplot as plt
year = [1950, 1951, 1952, ..., 2100]
pop = [2.538, 2.57, 2.62, ..., 10.85]
#Add more data
year = [1800, 1850, 1900] + year
pop = [1.0, 1.262, 1.650] + pop
plt.plot(year, pop)
Ta chạy đoạn code thì 3 điểm dữ liệu trên sẽ được thêm vào biểu đồ, nó cho ta một biểu đồ hoàn chỉnh và trọn vẹn hơn, thể hiện rõ nét hơn 'câu chuyện' mà ta muốn nói với người đọc thông qua dữ liệu.

BÀI TẬP
Bài 1: Labels
Bây giờ ta sẽ điều chỉnh lại một biểu đồ có sẵn, ta đã có một biểu đồ scatter về GDP bình quần đầu người ở trục-x và tuổi thọ ở trục-y. Đoạn code xây dựng biểu đồ đã có sẵn.
- Sử dụng hàm xlabel() và ylabel() để thiết lập nhãn cho trục-x và trục-y
- Sử dụng hàm title() để tạo tên biểu đồ
- Cuối cùng hiện biểu đồ bằng hàm show()
Bài 2: Ticks
Trong phần lý thuyết, ta đã học cách sử dụng y-ticks , bài này ta sẽ làm tương tự với hàm xticks() để tạo nhãn các mốc ở cột x, các giá trị 1000, 10000, 100000 sẽ được thay thế lần lượt là '1K', '10K', '100K'
- Sử dụng hàm xticks() để sửa nhãn trục-x
- Cuối cùng hiện biểu đồ bằng hàm show()
Bài 3: Sizes
Bây giờ, biểu đồ scatter là một vùng những điểm dữ liệu màu xanh và không phân biệt được chúng với nhau nhiệm vụ của ta là thay đổi một vài thứ. Ta sẽ thay đổi kích thước của điểm dữ liệu tương ứng với dân số.
Để hoàn thành, ta có 1 danh sách pop nó chứa dân số mỗi nước (tính bằng tỉ người), ta có thể thấy danh sách đó được thêm vào trong phương thức scatter() cho tham số s (size) ta có code và hình như bên dưới
plt.scatter(gdp_cap, life_exp, s = pop)

- Để tăng kích thước của các vòng tròn để nổi bật hơn, ta sẽ:
- import package numpy như là biến np.
- Sử dụng np.array() để tạo 1 mảng numpy từ danh sách pop, ta gọi nó là mảng np_pop
- Nhân đôi giá trị mảng np_pop
- Thay đổi tham số s trong plt.scatter() thay pop thành np_pop
Bài 4: Colors
Ta có đoạn mã sau
# Specify c and alpha inside plt.scatter()
plt.scatter(x = gdp_cap, y = life_exp, s = np.array(pop) * 2)
# Previous customizations
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000,10000,100000], ['1k','10k','100k'])
# Show the plot
plt.show()
Bước tiếp theo là ta sẽ làm cho biểu này nhiều màu sắc, để làm được điều đó, một danh sách có tên là col được tạo sẵn, nó chứa các màu tương ứng với mỗi quốc gia tùy thuộc vào quốc gia này thuộc châu lục nào. Dữ liệu Gapminder chứa danh sách châu lục và các nước trong châu lục đó, một từ điển cấu trúc tương ứng châu lục với màu sắc thể hiện, việc tạo từ điển này sẽ có trong các bài viết sau.
dict = {
'Asia':'red',
'Europe':'green',
'Africa':'blue',
'Americas':'yellow',
'Oceania':'black'
}- Thêm một thuộc tính c=col, trong hàm plt.scatter()
- Thay đổi độ mờ của các vòng tròn bằng cách thêm một thuốc tính alpha = 0.8 trong hàm plt.scatter(), alpha nhận giá trị từ 0 đến 1, giá trị 0 tương ứng với trong suốt hoàn toàn, và 1 thì ngược lại.
Bài 5: Additional Customizations
Nhìn vào đoạn code bên dưới
# Scatter plot
plt.scatter(x = gdp_cap, y = life_exp, s = np.array(pop) * 2, c = col, alpha = 0.8)
# Previous customizations
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000,10000,100000], ['1k','10k','100k'])
# Additional customizations
plt.text(1550, 71, 'India')
plt.text(5700, 80, 'China')
# Add grid() call
.........
# Show the plot
plt.show()
Bên dưới chú thích # Additional Customizations ta thấy có 2 dòng plt.text(), 1 dòng chứa chữ "India", 1 dòng chứa chữ "China"
- Thêm plt.grid(True) để tạo đường lưới trên biểu đồ
Bài 6: Interpretaion
Nhìn biểu đồ bên dưới và chọn nhân xét đúng

A) Các quốc gia ở châu Phi tương ứng màu xanh dương, có tuổi thọ thấp lẫn GDP bình quân đầu người thấp
B) Có sự tương quan nghịch giữa GDP bình quân đầu người và tuổi thọ
C) Trung Quốc có GDP bình quân đầu người và tuổi thọ thấp hơn Ấn Độ
BÀI GIẢI
Bài 1: Labels
# Basic scatter plot, log scale
plt.scatter(gdp_cap, life_exp)
plt.xscale('log')
# Strings
xlab = 'GDP per Capita [in USD]'
ylab = 'Life Expectancy [in years]'
title = 'World Development in 2007'
# Add axis labels
plt.xlabel(xlab)
plt.ylabel(ylab)
# Add title
plt.title(title)
# After customizing, display the plot
plt.show()

Bài 2: Ticks
# Scatter plot
plt.scatter(gdp_cap, life_exp)
# Previous customizations
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
# Definition of tick_val and tick_lab
tick_val = [1000,10000,100000]
tick_lab = ['1k','10k','100k']
# Adapt the ticks on the x-axis
plt.xticks(tick_val, tick_lab)
# After customizing, display the plot
plt.show()

Bài 3: Sizes
# Import numpy as np
import numpy as np
# Store pop as a numpy array: np_pop
np_pop = np.array(pop)
# Double np_pop
np_pop = np_pop * 2
# Update: set s argument to np_pop
plt.scatter(gdp_cap, life_exp, s = np_pop)
# Previous customizations
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000, 10000, 100000],['1k', '10k', '100k'])
# Display the plot
plt.show()
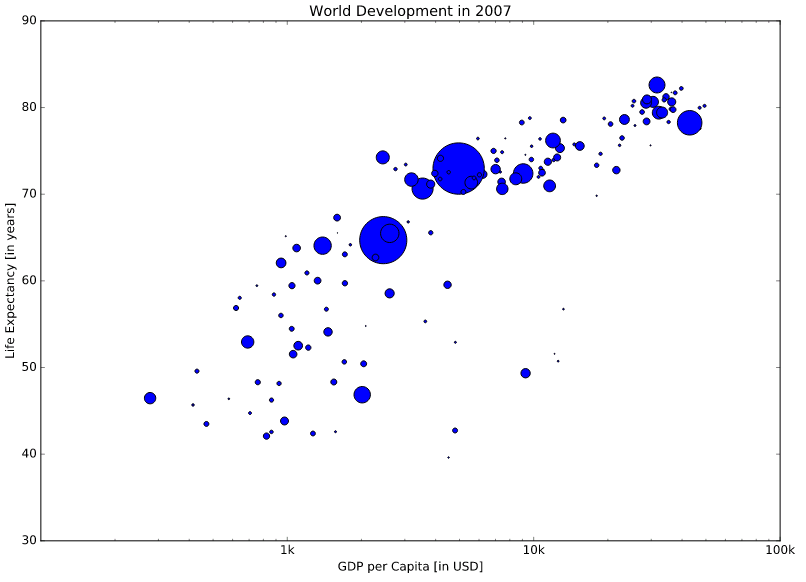
Bài 4: Colors
# Specify c and alpha inside plt.scatter()
plt.scatter(x = gdp_cap, y = life_exp, s = np.array(pop) * 2, c = col, alpha = 0.8)
# Previous customizations
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000,10000,100000], ['1k','10k','100k'])
# Show the plot
plt.show()

Bài 5: Additional Customizations
# Scatter plot
plt.scatter(x = gdp_cap, y = life_exp, s = np.array(pop) * 2, c = col, alpha = 0.8)
# Previous customizations
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000,10000,100000], ['1k','10k','100k'])
# Additional customizations
plt.text(1550, 71, 'India')
plt.text(5700, 80, 'China')
# Add grid() call
plt.grid(True)
# Show the plot
plt.show()

Bài 6: Interpretaion
Đáp án A